AI inference
Practicals from the POV of a software developer
張安邦 / Martin Chang
Slides and pictures licensed under CC-BY 4.0 / GPLv3+. Pick one you like
Disclaimer
- Opinions here are mine, not my employer's. Info shared is personal, not professional advice. Do your research and consult experts before deciding. My employer has no input or no say in this presentation.
- Nor I’m giving any proprietary information - I don’t want police raiding my home.
# whoami
- NSYSU CSE – Under Prof. Chang
- NVIDIA Senior SWE, Simulation Technologies
- FOSS developer when free
slides
Online view:
https://clehaxze.tw/slides/nsysu-sopc-2024
Offline download:
https://clehaxze.tw/slides/nsysu-sopc-2024.tar.zst
Open source work
- Maintains drogon, one of the fastest web framework
- GGML fork for RK3588 NPU and Tenstorrent
- Random OpenBSD and/or AI patches
Adgenda
- How do I get here
- How software developers use AI accelerators
- Trends in AI accelerators design
- What's making LLMs slow
- Trends in LLM architecture design
- The underground AI development scene
How do I get here
AI uses too much power
- Global warming is horrible enough
- Let's not make it worse
- Other FOSS developers also thinks so
I want to run an assistant locally
- But not with a 550W heat source in my room
- Also GPUs are expensive AF
- Monopoly is not good for end users
So I bought an RK3588 dev board
- Has 6 TOPS NPU*
- But it's not that simple
- Cheap
- High performance CPU
*Many limitations, really a convolution processor
Runing ML models on RK3588
- Export from PyTorch/TF to ONNX
- Pass ONNX to RKNN compiler
- Load compiled model on board
I wish it's that easy
- Input shape must be fixed
- Many issues with operators
- Compiler crash with large models
- Compiler OOM with large models
- MatMul on NPU slower then CPU
- etc...
Enough to get something done..
The piper TTS system
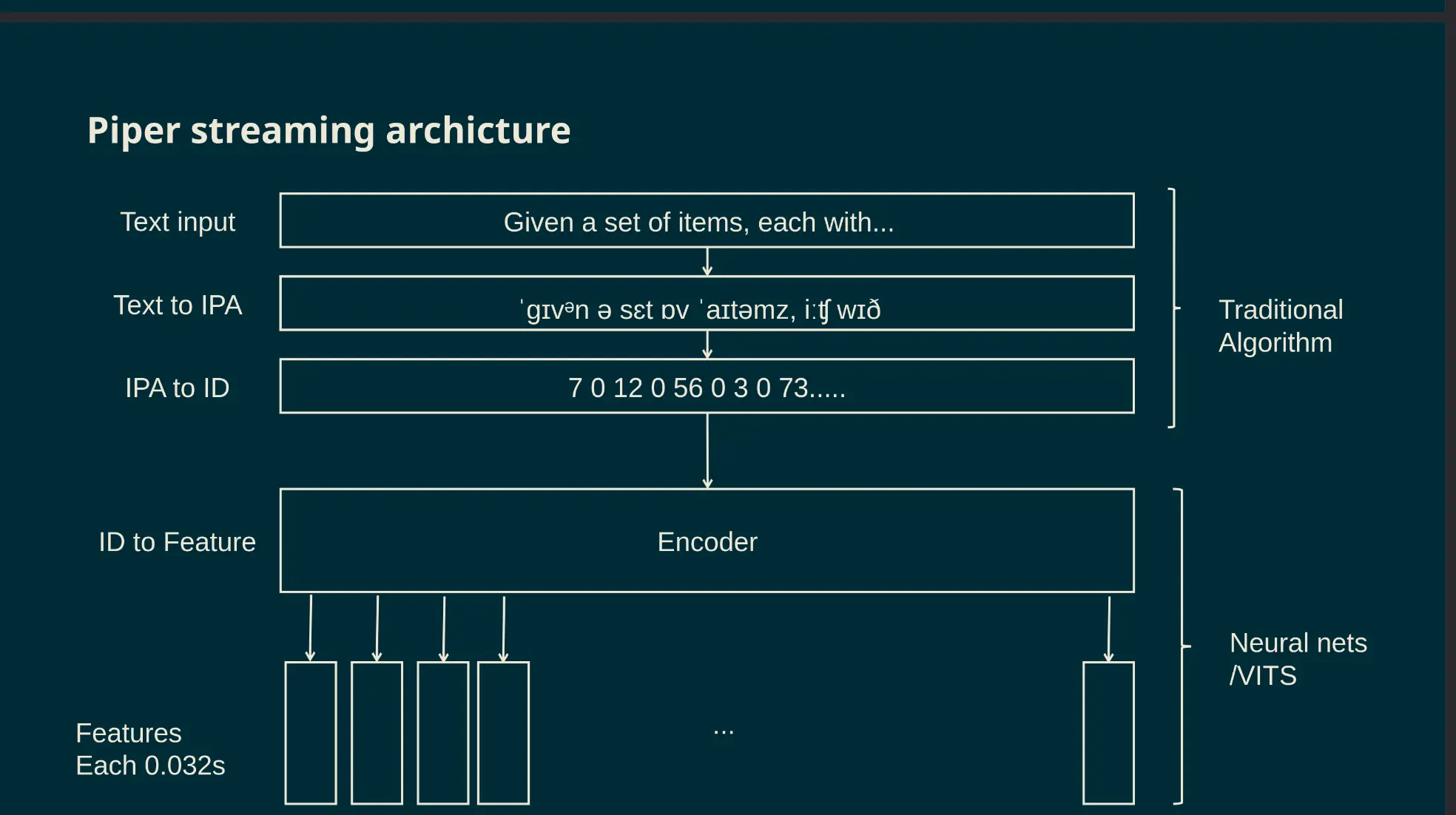
At least the decoder
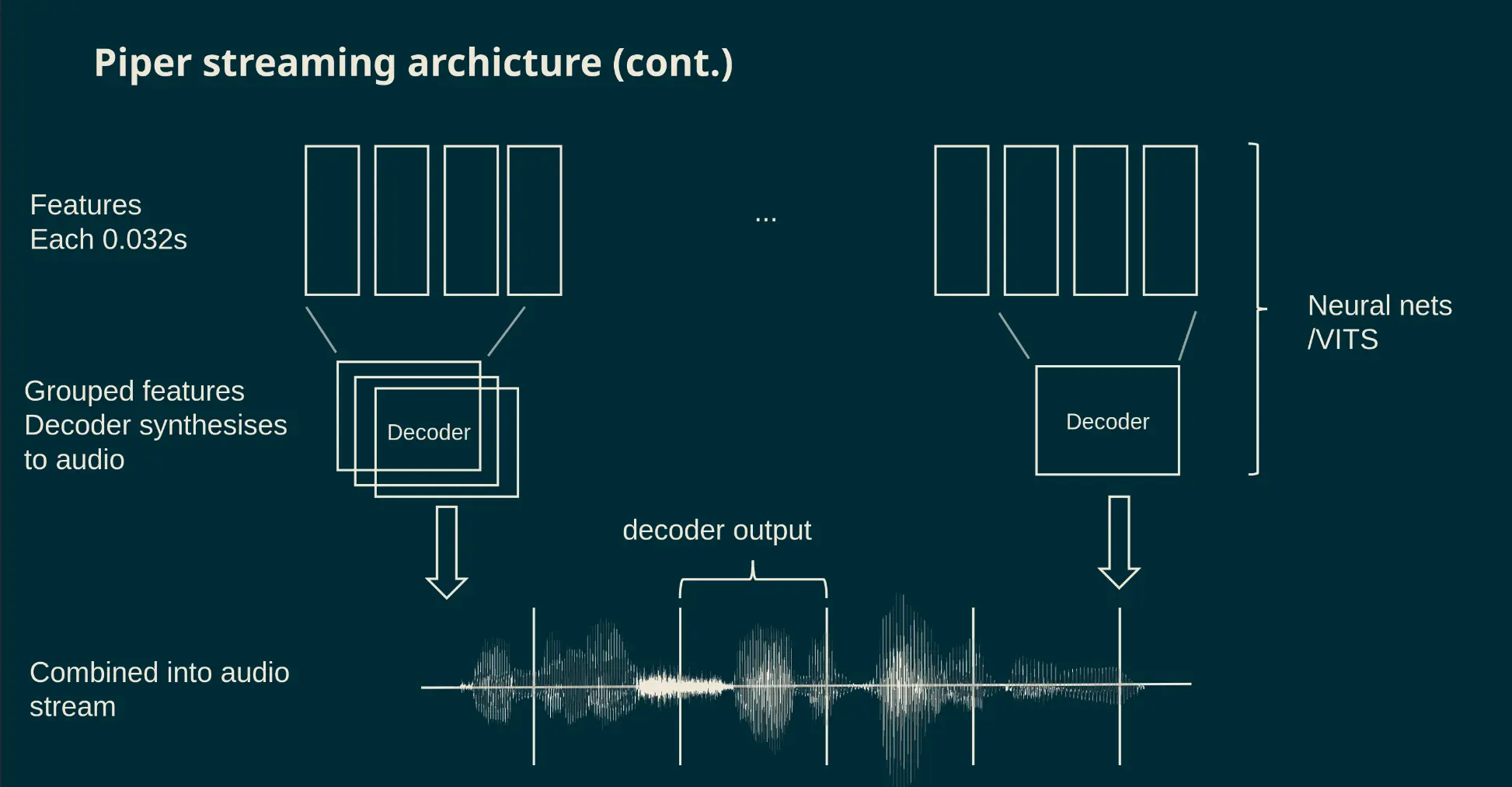
Getting Piper TTS to work on the NPU
A chain of many individual contributions
- rhasspy: Piper TTS for home assistant
- mush42: Separating En/Dec in Piper
- me: Infra for running decoder on RK3588
Whisper Speech-to-text
Someone did it - usefulsensors/useful-transformers
Now used by some for local transcription
Can I run LLMs.. yes
10 GFLOPS when batch=1
Ditched RK3588 for Tenstorrent
- That's a story still happening
- Good theoretical performance
- Bad software.. but the community is working on it
Progress so far
- With help up a few others
- Just got Gemma 2B working
- 7 patches submitted
- Working on Qwen2 and GGML support
How software developers use AI accelerators
- Download/train a model
???
- Profit
How software developers use AI accelerators
- Download/train a model
Pain and suffer
- Profit
Two routes
- Model compilers
- Bring your own code
Model Graph
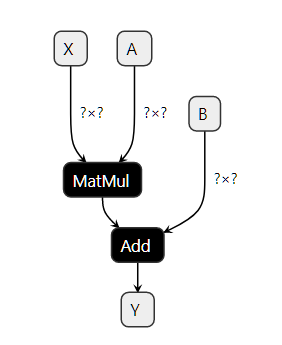
Model compilers
- Compile ONNX/PyTorch into something the accelerator can understand.
- Optimizes the model graph for speed
To compile the models
from rknn.api import RKNN
rknn = RKNN()
rknn.configure(target_platform="rk3588")
rknn.load_onnx("/path/to/model.onnx")
rknn.build(do_quantization=False)
rknn.export_rknn("/path/to/model.rknn")
And to run them
from rknn_lite.api import RKNNLite
rknn = RKNNLite()
rknn.load_krnn("/path/to/model.rknn")
out_data = rknn.infernece([input_data])
It works until it doesn't
- Simple, but you can't fix it if something goes wrong
- Sometimes errors are siltent too
(cont.) stuff you don't know until you try
- Input shape (sometimes) must be known at compile time
- Some operations not supported
- Limitation on shape for certain operations
- etc..
The average ML engineer doesn't know all these.
Nor pretrained models care.
Bring your own code
You are given API to make the accelerator do stuff. And you are responsible for the rest.- Easily adaptable to newer hardware
- Don't need to wait for bug fixes
- Usually you have the CPU to pick up unsupported operations
- Someone gotta do the hard work
Typical BYOC bring up
- Pick a framework (or not)
- Register your backend with the framework
- Write your device memory allocator
- Find nodes in graph which the device supports
- Run weight re-layout
- Use the NPU during inference
void ggml_compute_forward_mul_mat(...) {
#elif defined(GGML_USE_RKNPU2)
// Run matrix multiplication on NPU if possible
if (ggml_rknpu2_can_mul_mat(src0, src1, dst)) {
// fprintf(stderr, "rknpu2\n");
if (params->ith == 0 && params->type == GGML_TASK_COMPUTE) {
ggml_rknpu2_mul_mat(src0, src1, dst, params->wdata, params->wsize);
}
return;
}
#endifvoid load_all_data(...) {
#elif defined(GGML_USE_RKNPU2)
case GGML_BACKEND_GPU:
if (ggml_rknpu2_can_mul_mat_b(cur) == false) {
break;
}
// Copy and reorder data for NPU
ggml_rknpu2_transform_tensor(cur->data, cur);
if (!use_mmap) {
free(cur->data);
}
break;
#endifvoid ggml_rknpu2_mul_mat(...) {
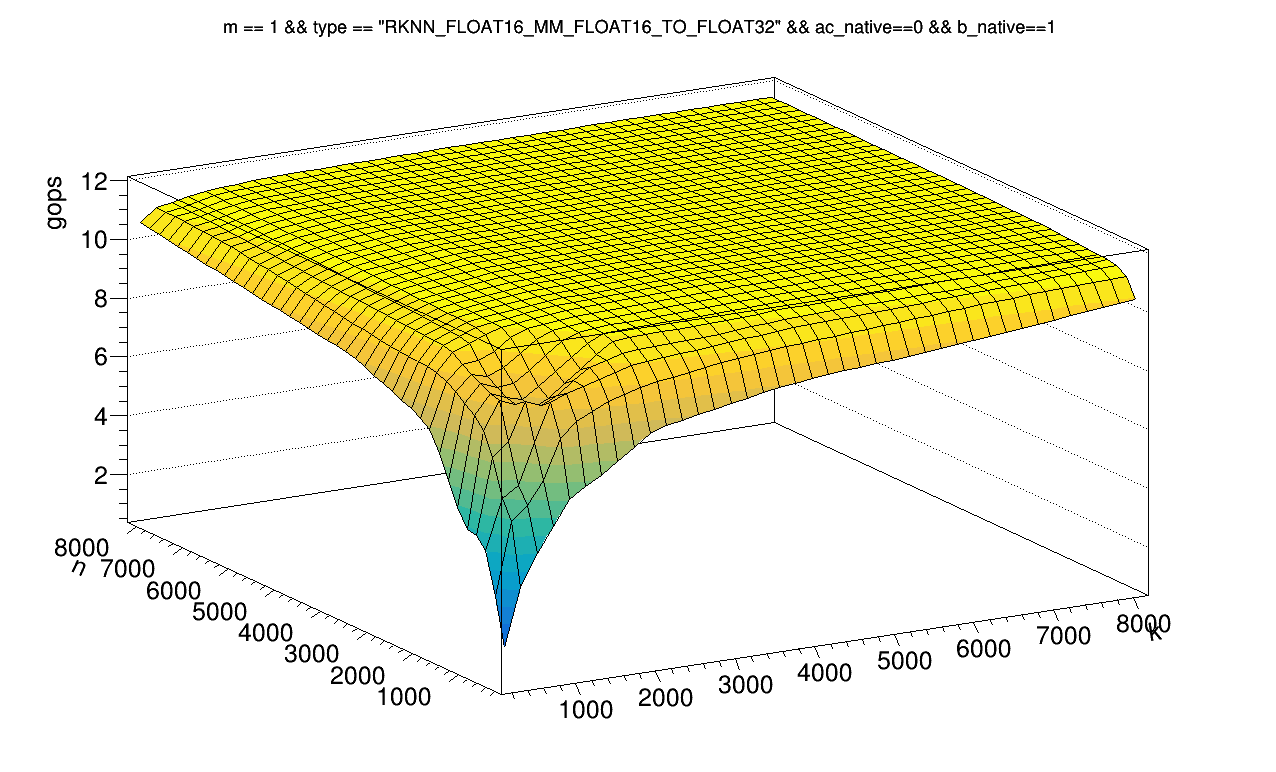
struct ggml_rknpu2_matmul_kernel* kernel = ggml_rknpu2_matmul_kernel_find(m, k, n, pack->type);
// GGML will switch batch size on the fly. So we need to create a new kernel if the batch size is different
if(kernel == NULL)
kernel = ggml_rknpu2_matmul_kernel_create(m, k, n, pack->type);
...
int ret = rknn_matmul_set_io_mem(kernel->matmul_ctx, kernel->A, &kernel->matmul_io_attr.A);
GGML_ASSERT(ret == 0);
ret = rknn_matmul_set_io_mem(kernel->matmul_ctx, pack->B, &kernel->matmul_io_attr.B);
GGML_ASSERT(ret == 0);
ret = rknn_matmul_run(kernel->matmul_ctx);
GGML_ASSERT(ret == 0);
...
memcpy(dst->data, kernel->C->virt_addr, m * n * sizeof(float));
BYOC example
See llama.cpp #722 and useful-transformersWhat's making LLMs slow
DRAM bandwidth
- Fundamental limitation: max speed = model_size/ram_bandwidth
- LLaMA 3 8B is 16GB @ FP16
- Desktop has ~ 60GB/s
- Max: 4 tokens/s
:(
Make VSCode highlighter happy :)
Matrix matrix vector multiplication
- Most processors are optimized for matrix-matrix multiplications
- Usually we batch to solve this..
- LLM is already slow enough. Don't make it slower
source: 黎明灰烬. CC-BY-SA 4.0
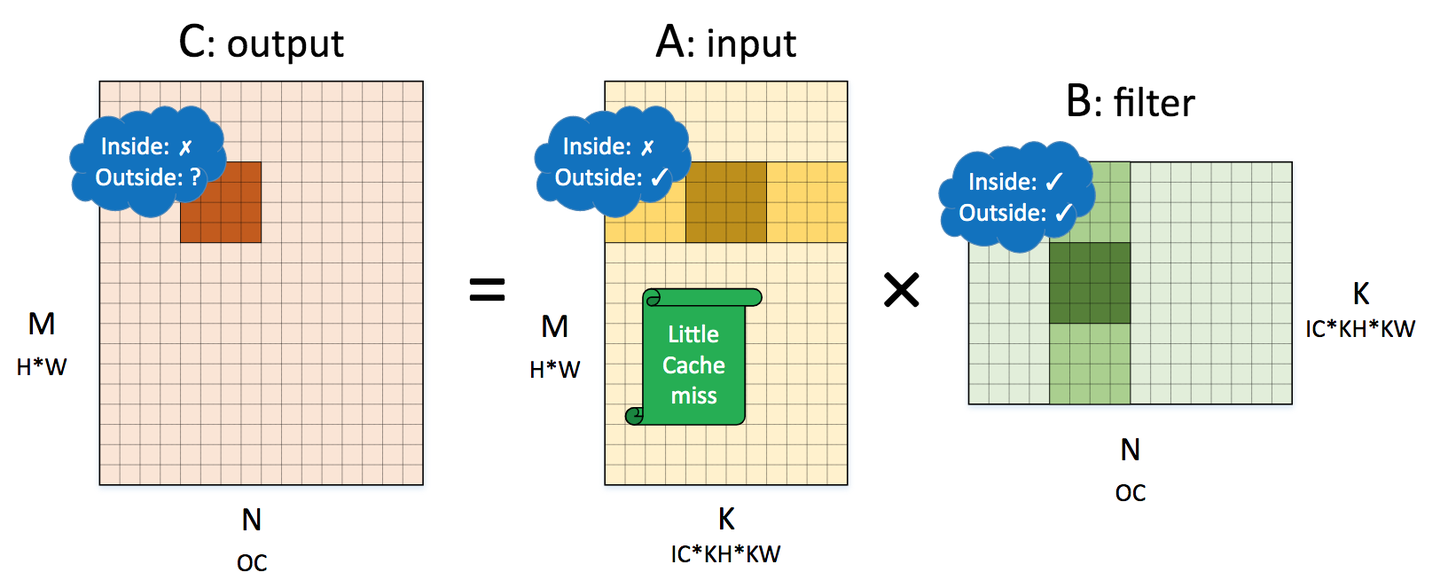
Transformer's O(N^2) complexity
- For attention of N tokens. Generates a
[N, N]attention matrix - FlashAttention, etc.. tries to reduce the pain
- But never completely solved in Transformers
Trends in accelerator designs
Low and sub-byte precision math
- Reduced bandwidth
- Lower power in MAC operations
- NVIDIA will use FP6 on Blackwell
- LLMs trained on FP16

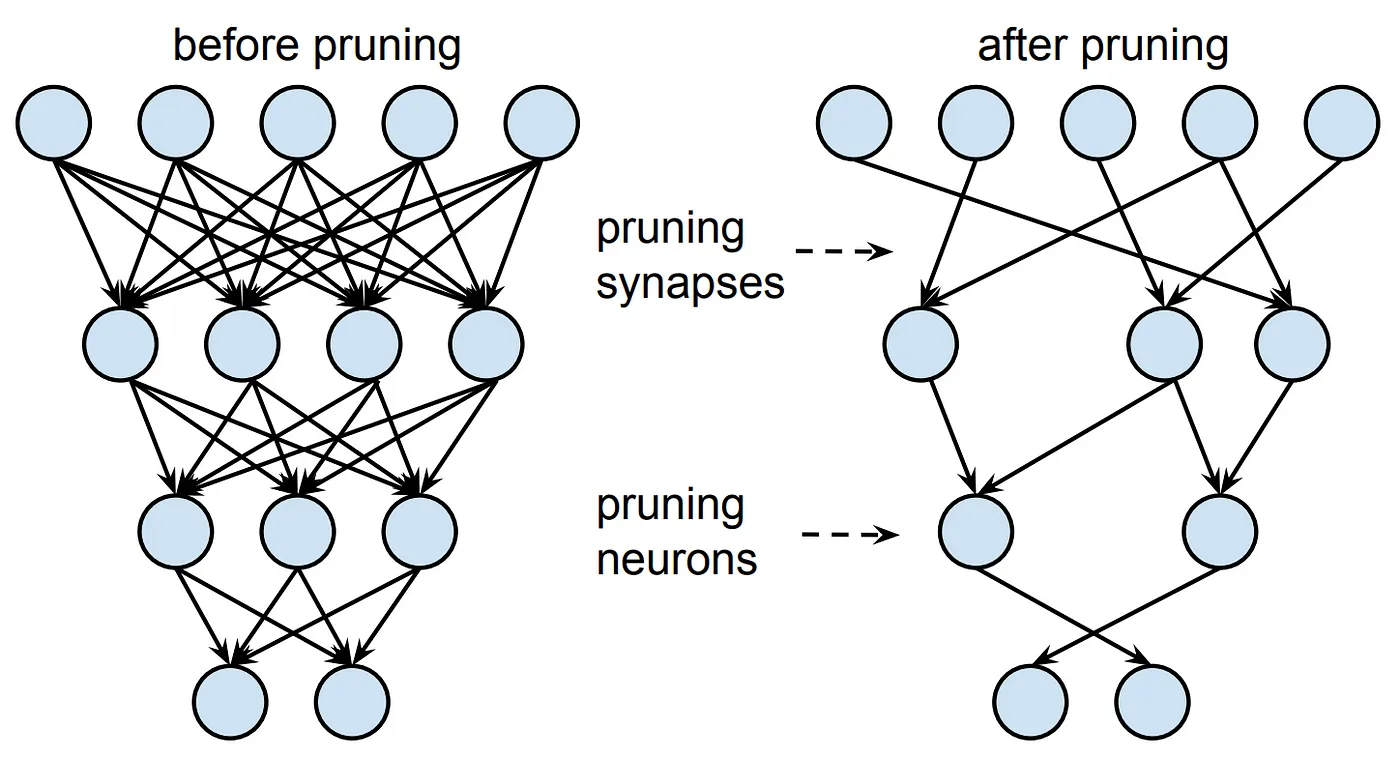
Sparsity
- 90% spare = 10x performance
- In practice difficult to do
- Active research area
source: arXiv:1506.02626
More SRAM!
- Attention is expensive and large
- Keep as much data on chip as possible
Sharing Exponent
Tenstorrent. Apache 2.0
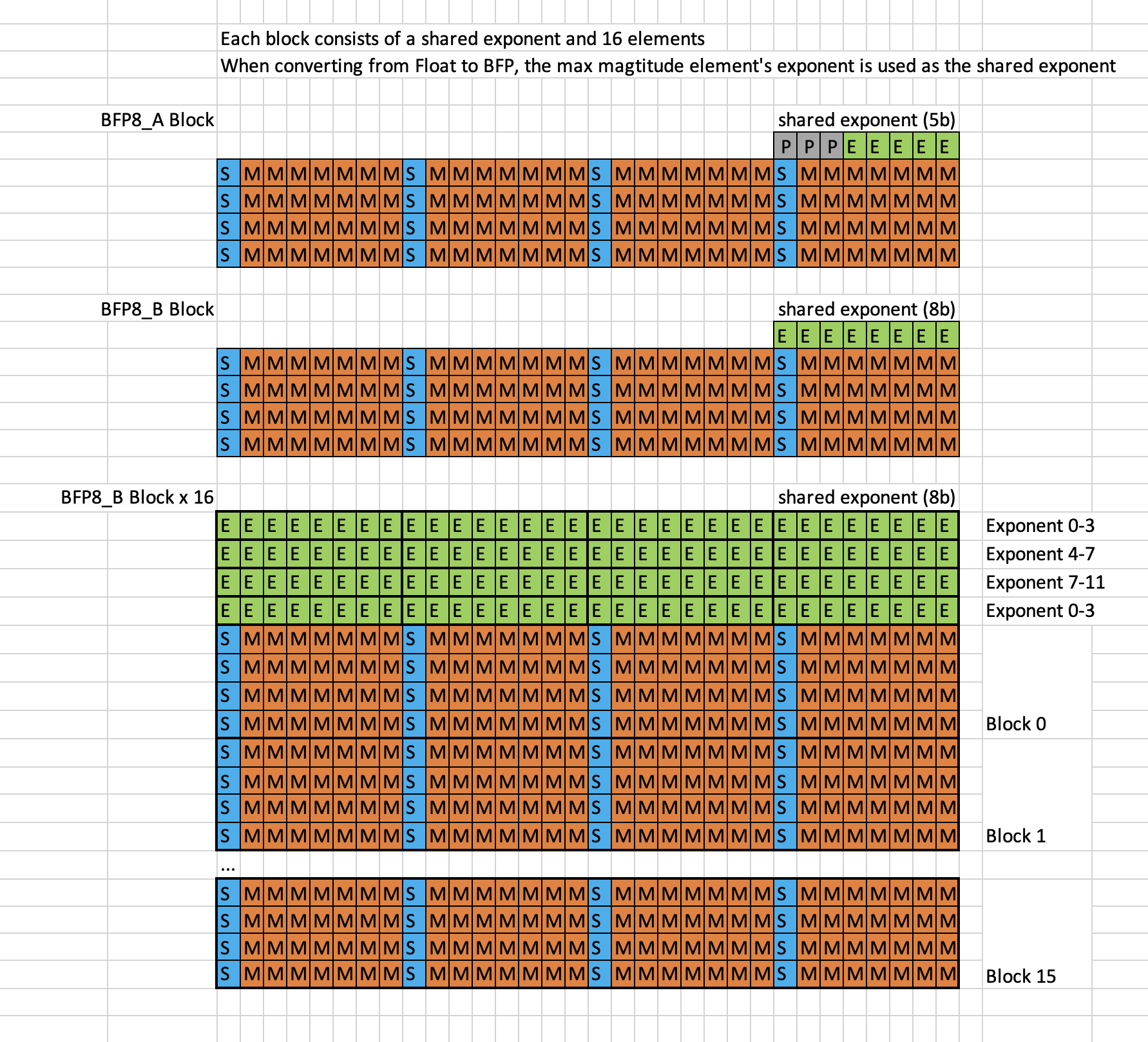
GGML has the same idea
#define QK4_0 32
typedef struct {
ggml_half d; // delta
uint8_t qs[QK4_0 / 2]; // nibbles / quants
} block_q4_0;Trends in LLM architecture design
Grouped Query Attention
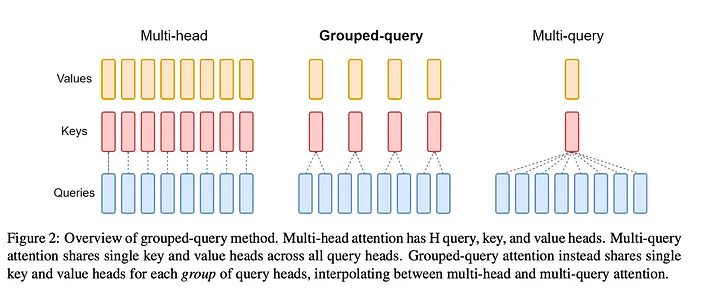
- Let multiple tokens share attention
- LLaMA 3, OpenELM
Attention free models
- RecurrentGemma/RWKV/Mamba
- Attention is slow, let's get rid of it
- Technically infinite context window
- Much faster and efficient. But text generation quality is lightly worse
Honorable mention: Linear Attention
- Try to get rid of the quadratic complexity by exploiting symmetry
- Doesn't really compete with full Multi Head Attention in performance
The underground AI development scene
Not only the chip companies are interested in AI
Hardware RE and UMD/upstream efforts
- V831 NPU
- VeriSilicon VIPNano-QI.7120
- RK3588 NPU
A lot of interest and developer efforts
Not even 1st party. Just people wanting faster, lower power LLM
Future work
- Keep on doing what I'm doing
- Look into AMD NPU
- Intel NPU is
boringeasy, contribution welcomed
Thank you
You can find me in
- email: marty1885 \at protonmail.com
- Discord: @marty1885
- OFTC IRC: marty1885 on #ml-mainline
- Matrix: @clehaxze:matrix.clehaxze.tw
- GitHub: marty1885